An Opinion about AI: ChatGPT and More

I’ve been hostile to “AI” as a term for a long time. Probably more hostile than I should be, but hostile I have been. I've changed my mind somewhat in the past several months, for reasons we'll get to, but I'll try not to bury the lede. Here’s my current opinion on ChatGPT in particular, the AI iteration that everybody's talking about as I write this:
It’s the first “modern AI” that I have personally found useful, but even then, I only find it limitedly useful. I use it (when its servers aren’t overloaded) as a very specific type of search engine, for the types of questions I would otherwise Google, namely esoteric, fact-based questions like “What’s the best way to dedupe a list in Python?” or “What’s the origin of the phrase ‘For all intensive purposes’?”1
This tries to paint the general contours of what ChatGPT is and how to use it, but there’s a lot going on behind the scenes. Starting with:
AI - WTF Is It?
Ugh, this is part of the reason I’ve been so hostile to AI. It just doesn’t really have a definition. Or maybe its definition is so broad as to not mean anything.
You can Google, or ask ChatGPT I guess, for standard/accepted definitions of AI if you want to, but I’m going to provide a definition of my own because I want to focus on a few specific aspects of the topic. To be clear, this is my definition of AI, for me, right now, in the context of this post. Other definitions may be more appropriate for others in other contexts, but for now I think I have two definitions of AI, a broad definition and a narrow definition.2
I think my broad definition is relatively uncontroversial. I broadly define Artificial Intelligence, or AI, as the ability for computers (or machines more broadly) to mimic human behavior. I first encountered AI in video games. The behavior of enemies and other Non-Player Characters (NPCs) in video games is referred to as AI, and advanced video gamers are constantly finding ways of hacking video game AIs to change the nature of the gameplay in fun ways.
To whatever extent you agree with my broad definition, a reasonable response would be to ask what the fuss is all about. Video games and other machines-behaving-like-humans have been around for decades. Why all the attention now?
I think all the recent attention is focused on a more narrow version of AI. AI can be narrowly defined to be the use of of deep learning to get computers to accomplish tasks that have historically proven difficult or impossible to achieve, especially with regard to unstructured data such as images, video, audio, and text.
There are at least two problems with this definition. First, it depends on two other ambiguous concepts, deep learning and unstructured data, both of which we’ll come back to. And second, it leaves out a lot of things that folks frequently refer to as AI, most obviously video game NPCs and (most) car-building robots.
I use this definition, despite its flaws, because it gets to the reason I think AI has gained so much attention in recent years, especially in business contexts. I’ll be using this narrow definition for the purposes of this blog post, but for clarity’s sake, I’m going to try to avoid using the term when possible, opting instead for more precisely-defined concepts.
AI (Narrowly-Defined) Circa Mid-2020
In the summer of 2020 a friend of mine who writes about data science and analytics for a major business publication called to ask me about AI. In particular, he was doing research into the then-newly released language model called GPT-3, and he wanted to know my opinion about how GPT-3 might affect companies’ use of technology and data science.
At the time, I had three distinct opinions, all of which I mostly stand behind as I write this in late 2022. The three opinions are:
Recent advancements in deep learning, including GPT-3, are nothing short of astounding intellectual achievements.
I don’t really care. It’s not going to affect my job or my team, despite the fact that the recent technological advancements are in my very field of “data science.”
Maybe the recent advancements really are approaching something like consciousness?
I recognize that these three could be construed as disagreeing with one another, and maybe they do, which would mean that at least one of them would have to be wrong. But even if they are contradictory, I think they’re justified in the associated “vibes,” as the kids say. Let’s take them one at a time.
I. Astounding Intellectual Achievements
An underappreciated feature of technology in general, and data science in particular, is that if you’re trying to get a machine to perform a certain task, it can be really hard to predict which tasks are going to be easy and which tasks are going to be hard for the machine.

There are many tasks that are so easy for people that they don’t even seem like “tasks,” but that are nigh impossible for computers. Most notably for AI, many of the tasks that are easy for people but hard for computers involve identifying objects or concepts based on images, video, audio, or text.
For example, if you listened to an audio recording of me saying something boring like “My name is Ian,” you would immediately know a bunch of things, starting with learning what my name is. But you may not notice that you also would know a host of other things, such as the timber of my voice, the quality of the recording, the fact that I was speaking English in an American accent, and so on.
Those “tasks” are so easy for you that you don’t even notice that you do them, but until very recently computers could do none of these things. Part of the reason computers have struggled so much with these tasks is because computers are highly “structured” whereas images, video, audio, and text are “unstructured.”
Computers can be thought of as tools for processing inputs, and computers historically have required their inputs to be “structured” in a very particular way. To give an example, let’s look at something computers are very good at: arithmetic.
If you were to open up a calculator, type in 943 + 347 and hit the equals sign, the calculator would instantly return 1290, the correct answer. But if you were to hold that same calculator and ask it aloud, “What is nine hundred forty-three plus three hundred forty-seven?” it should be obvious that even if you ask very nicely, it wouldn’t give you any answer, let alone the correct one.
In some sense, the reason your calculator can’t give you an answer if you ask it in English (or whatever) is because you haven’t “structured” the question properly for the calculator. You need to give the calculator the question in the format it was designed to work with. Any other format just won’t work.
This formatting problem scales all the way up to modern computers. Computers are very good at processing large amounts of data to derive statistical or analytic insight, but only if the data is formatted a certain way. Historically, data science techniques could only be applied to data that was referred to as “structured,” or stored in rows and columns, à la an Excel spreadsheet. In the same way that yelling at your calculator and hoping to do arithmetic was never going to work, trying to apply data science techniques to anything other than data stored in rows and columns was also never going to work.3
So what happened? Deep learning happened.
To massively simplify, at the intersection of statistics and computer science is a field called “machine learning.” Despite its fancy name, machine learning is just an extension of elementary statistics.4
The field of data science has largely grown out of applying machine learning to more and more areas, relying almost entirely on structured data. From baseball to movie recommendations to pregnant teenagers, data science techniques have revolutionized quantitative predictions across countless domains.
Neural networks are a certain kind of machine learning that I never found particularly useful. They always seemed overly complicated compared to other types of models such as regular regression or decision trees, but they (along with a massive increase in the amount of available data and computational power) turned out to be the key to getting computers to process unstructured data.
Several remarkably clever breakthroughs in the past decade or so have enabled computers to turn unstructured data (i.e. images, video, audio, and text) into structured data that neural network models can process.5 As these breakthroughs took hold, neural networks grew in number, size, and variety to the point that they collectively became known as "deep learning." And it is deep learning models that, for the first time, were able to effectively process unstructured data.
This is the part that’s so amazing. With deep learning, computers can now perform tasks that have historically been literally impossible.
II. Wherein I Don’t Care
So if this is all so amazing and impressive, why don’t I care? I’m a data scientist after all, and all these amazing breakthroughs have happened in my domain. How could I not care?
At this point, I have to admit that my interests are somewhat parochial. I’ve spent my career as a data scientist digging into into companies’ databases, finding existing patterns, and informing decision making. The older techniques work just fine on this type of analysis. I just don’t need deep learning to generate valuable insights. Most databases are structured, after all.
This is another reason I’ve been so hostile to the term “AI.” There are so many organizations with so much (structured) data that they haven’t even used yet. Let’s do “regular” data science first. I am confident that every organization above a certain size can improve their operations in one way or another using established data science techniques, and focusing on the fancy new “AI” distracts from more down-to-earth opportunities while also making data science feel more out of reach for “normal people.”
In this sense, modern companies’ relationship to AI can be compared to, say, railroad companies’ relationship to quantum mechanics 100 years ago. The 1920s saw massive breakthroughs in theoretical physics. The breakthroughs were real and amazing, but they just didn’t have much direct impact on the railroad companies of the day.
I expect that the impact of current deep learning breakthroughs on most modern businesses will be similar to the impact of quantum mechanics breakthroughs on railroad companies in the 1920s. Maybe some impact eventually, but the companies still have to operate in their normal paradigms, at least until applications become clear.6
III. Uh, Maybe Consciousness?
This is where we stray into some less-than-fully-grounded speculation. If you’re not interested in philosophical implications of communication and theories-of-mind, you can feel free to skip to the next section, under the header “No Really, What’s All the Fuss about?”
A way to describe modern deep learning, and indeed all machine learning, could be something like “brute-force statistical pattern matchers which blend up input data and give you back a slightly unappetizing slurry of it when asked.” But then I came across a blogger who said something like, “Your mom is a brute-force statistical pattern matcher which blends up input data and gives you back a slightly unappetizing slurry of it when asked.”
And I realized I don’t really have a comeback to this particular schoolyard insult.7
The insult was part of an early-2019 blog post discussing GPT-2, the precursor to GPT-3, the model on which ChatGPT was built. Before that post, I hadn’t thought of machine learning models as really “learning” per se. Sure, machine learning is called machine “learning,” but what it’s doing isn’t “learning” so much as “systematically updating parameters in increasingly complicated equations to minimize loss functions.”
In this sense, the term “machine learning” is a bit misleading because the way machines “learn” is really different to the way people learn, and calling it “learning” can create a misperception of what models do and how they do it. In fact, this is why I generally try to avoid the term when I’m building and describing models, opting instead for terms like “predictive models” or “algorithms.”
That said, if there is a sufficiently well-built model (or “AI” if you like) that can respond to general questions as well as a human, and whose answers are indistinguishable from a human’s, is there a principled reason to say that the model isn’t “thinking?”
I honestly don’t know. And I really don’t know what to do about ethical and safety implications of these increasingly large and complex black-box language models. If you’re interested in looking into the philosophical implications of these models, there are some very smart people working on it.
But I’m not one of them, so maybe it’s time for me to get back to some more practical questions, like:
No Really, What’s All the Fuss about?
So far we’ve only covered “AI” as of mid-2020, two-and-a-half years ago. If these breakthroughs are so amazing, why didn’t it capture everyone’s attention then?
Obviously, part of the reason is that there was something else going on at the time, monopolizing everyone’s attention, but that’s not the whole answer.
First of all, there actually was plenty of buzz and attention in certain circles when GPT-3 came out, but that’s always the case about any niche topic. The main reason it, and other language models, didn’t garner as much attention at the time is because they were really hard to work with.
Not only did you have to be comfortable with downloading and running code from a centralized repository like Github, you needed to have access to huge computing power in order to run it properly. As such, the new models were only practically accessible to machine learning professionals, and even then, not all machine learning professionals. You may be able to count me as a “machine learning professional,” but as I’ve mentioned, I never used these models for anything.
The recent buzz and attention come, not from the machine learning advancements themselves, but because ChatGPT is finally accessible to normies. So far, I’ve been using the terms “GPT-3” and “ChatGPT” almost interchangeably, but they are not the same thing. GPT-3 is the language model itself whereas ChatGPT is an easy-to-use user interface for interacting with the underlying language model. Now that the model (GPT-3) has a user-friendly way to interact with it (ChatGPT), it has (for the first time) become useful for non-experts. Which begs the question, how should non-experts use it?
How I Use ChatGPT
As mentioned above, I am amazed and surprised that a generalized deep learning model has been built that’s good enough to use for anything other than creating silly semi-plausible text adventures or generating images of people who don’t exist or whatever. These cutting-edge AI models, while amazing, have always seemed like fun toy projects. Very impressive that someone was able to pull it off, but so what? Until ChatGPT I’ve thought of AI models similar to how I thought of skateboarder Tony Hawk when he first pulled off The 900. An undeniably outstanding feat, but not likely to affect my life, or especially my career, very much.
And even with ChatGPT, that still feels ~80% true. ChatGPT is really cool, and particularly useful for a couple really specific things, but the world still runs the same today as it did a month ago. I just don’t anticipate my job or my field to change much due to these new AI models.8
So what is it useful for? Asking esoteric, fact-based questions that I would otherwise Google.
I happened to be doing some work in Python the other day, and because I’m not a super strong Python coder, I had a specific question about how to remove duplicate entries from a list that I was working with. Until a few weeks ago, I would have Googled the question and found the answer on Stack Overflow or something.
This approach works fine, but there are two relatively minor annoyances associated with it. First, when Googling a question, you have to filter through the search results to find the answer yourself. Depending on how specific the question is, the solutions you find in the search results might be answering a slightly different question than the one you asked, even if the information is accurate.
The second annoyance is SEO. In the roughly 25 years Google has reigned as everyone’s window to the internet, as an ad-supported platform, an entire industry of advertisers has sprung up around gaming Google’s ecosystem, called “Search Engine Optimization” or SEO.9 I’m not the first to point this out, but if you search something innocuous on Google, the first several results will likely be riddled with ads, sometimes so many that it’s almost impossible to find the information you’re looking for among them.
Google vs. ChatGPT
As an example of how Google performs versus ChatGPT, let’s look at a question I had when writing this post:
Is the word “about” capitalized in titles?
You may have noticed the title of this post is “An Opinion about AI: ChatGPT and More.” According to the rules of grammar, I’m aware that most words are supposed to be capitalized in titles, but some “smaller” words like “the,” “and,” and “to” aren’t, unless they’re the very first word. I wasn’t sure which category the word “about” was in, so I looked it up. Both in Google and in ChatGPT.
Let’s see what Google returns:
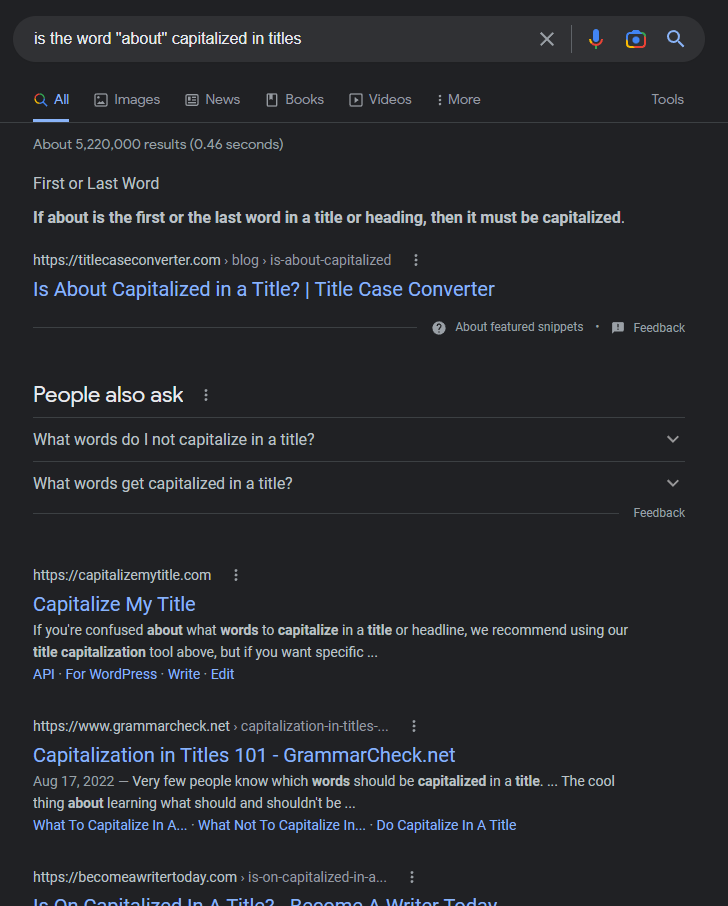
In this case Google does a relatively good job! It directly gives the answer “If about is the first or last word in a title or heading, then it must be capitalized,” and the front page is (entirely?) ad-free. But it’s not perfect. For one thing, the result technically doesn’t answer my question. It says what to do if “about” is the first or last word, but it doesn’t say anything about what to do if it’s a middle word (as is the case for me).
Now, from context I can reasonably infer that it shouldn’t be capitalized, but I still feel like I need to double-check, which means clicking into one of the links. Let’s see where the first one goes:
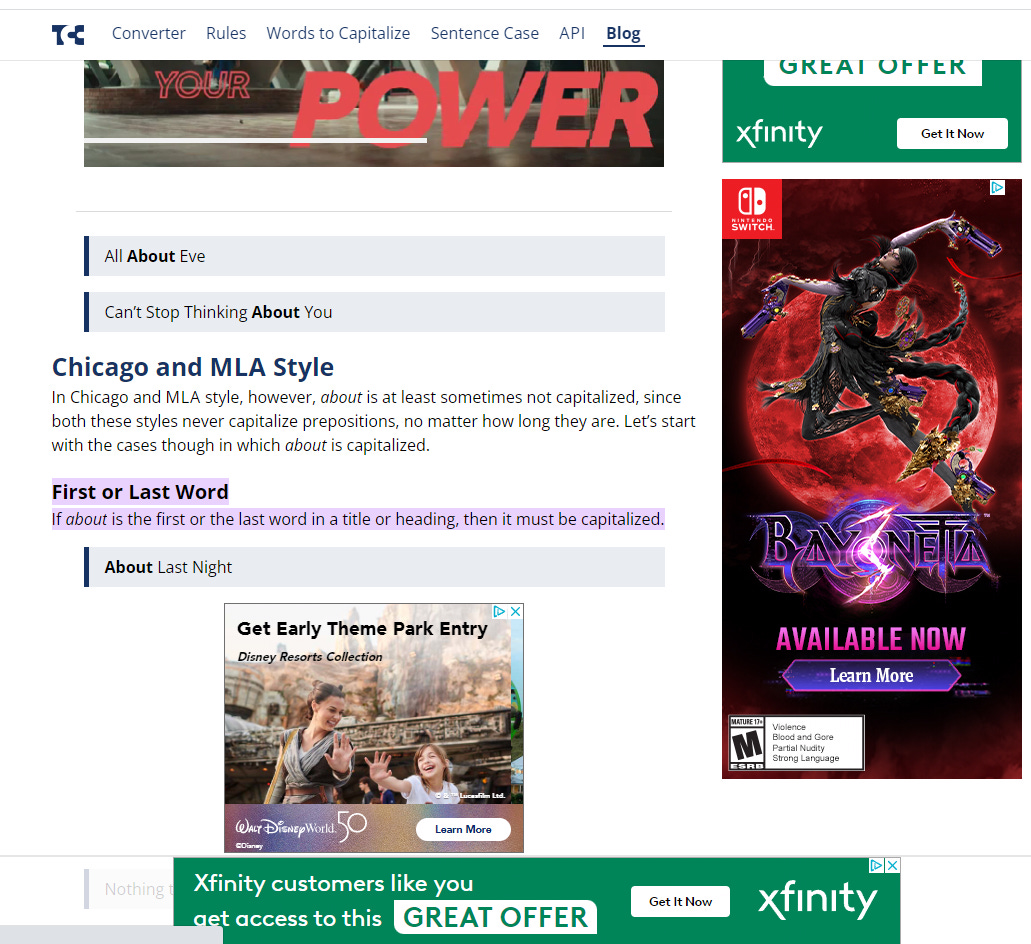
This is insane. You can’t tell here, but it took several seconds for all these ads to load, and each time a new ad finished loading, the page’s content bounced all around the screen as I was trying to read it. Not only that, but while Google was smart enough to zoom into and highlight the part of the page it thought I wanted to see, it still doesn’t technically give me the answer I’m looking for. The closest this page gets to answering the question is to say, in the non-highlighted text, that “about is at least sometimes not capitalized.” 🤦♂️
And that’s not to mention the barrage of ads. I measured it, and it turns out that a full 45% of the screen real estate, almost half of the entire screen, is taken up with ads. If I’m generous and count both the highlighted text and the entire paragraph that (sort of) has the answer in it as the valuable content of the page, 16%, less than one sixth of the screen is devoted to actually answering my question, and even then it’s a little hard to parse.
And that’s just the first result. Rest assured that the other results are just as bad.
How does ChatGPT do?

It just correctly answers the question. No ads. No SEO. No nonsense. Just the answer.
In fairness, I will say that it took a couple seconds to “think” before typing out the answer, character-by-character, as if it were typing,10 so it did take a little longer than Google to return a result. That said, the difference in return time is small, especially if you take into account the amount of time it took to load the ads after clicking through to the first result. Also, here in the first few weeks of ChatGPT, its servers are frequently overloaded to the point where you can't use it at all, which is obviously a big strike against it, but I imagine that problem will mitigate as the team right-sizes its servers and the buzz and attention naturally die down.
But this is the type of thing that I use ChatGPT for. I was genuinely unsure if I should have capitalized the word “about” in my title, and ChatGPT was able to help me more directly and less annoyingly than Google.
One last thing about how I use ChatGPT. I play with it like a kid plays with a toy. I see what types of stories it can tell, what kind of jokes it can make up, what kinds of poetry it can write and so on. These “toy” uses are real uses, and a lot of fun! I’m just suspicious that once the novelty wears off, the toy uses will have run their course.
How not to use ChatGPT
Now that we’ve covered how to use ChatGPT, let’s briefly go over how not to use it.
First and foremost, it is incumbent to not use ChatGPT for anything unethical or illegal. The developers at OpenAI, the creators of ChatGPT, have put in some safeguards to try to disallow ChatGPT from giving unethical or (especially) illegal answers, but just like video gamers hack their games’ AI, some users have already found ways to “hack” ChatGPT to get around its safeguards. I’m not going to describe the hacking methods here, because they’re at least in an ethical “grey zone," but trust me. It’s happened.
Relatedly, but perhaps less dramatically, ChatGPT is also not particularly useful for anything that’s even remotely controversial. For example, while writing this post I struggled with how to define “AI,” partly because its definition is somewhat controversial. In theory, as mentioned above, I could have asked for ChatGPT’s definition, but whatever results I got would have probably been at least incomplete. They might have even been argumentative.
That’s why I focus on factual questions rather than opinions or news or whatever. ChatGPT is best for queries about well-established, but potentially not widely-known, factual information.
But it even falls down in this domain sometimes! In an email the other day, I referred to the idea of a “garden path sentence,” which is a well-established, but not particularly widely-known concept. When I used the phrase, I thought it might be necessary to explain what I mean by “garden path sentence,” so I asked ChatGPT to give me a definition:

At first glance I thought “Great! This is a nice, pithy description of a somewhat esoteric concept.” But then I read it a little more carefully. Check out the second-to-last sentence in the response, highlighted below:

This explanation seems reasonable at first, but if you pay attention, it’s not right! The sentence never implies that the old man owns the boat. There’s nothing about ownership at all. The classic “old man the boat” garden path sentence works because “old man” is usually interpreted as adjective-noun, i.e. “old” is the adjective modifier of the word “man,” but when the sentence abruptly ends with “…the boat,” we have to reinterpret the entire sentence to realize “old” is the subject and “man” is the verb, completely changing the sentence’s meaning.11
To be fair, this is a pretty subtle point that’s easy to mess up. Messing with intuition is the whole point of garden path sentences, but I do like it as an example of how ChatGPT can get tripped up in subtle ways that you might not even notice.
Conclusion
Despite the continued amazing progress on modern deep learning models, “normal data science” remains extraordinarily valuable (and largely untapped) for many organizations. And I really don’t know what to think about the philosophical implications of a machine that can answer questions the same way a human does.
ChatGPT is a fascinating, surprisingly useful tool, and I’m excited to see how it grows. But almost 5,000 words later, I don’t think I can put it better than Nate Silver on the day ChatGPT was released:

The phrase is actually “for all intents and purposes,” not “for all intensive purposes,” and when I first thought of the phrase as an example, I wasn't even sure that ChatGPT would get it right. I checked, and it does turn out to get it right:

Even when I’m trying to be really careful, I can’t help but equivocate about the definition of AI. I can’t even give a single definition!
Since we’re touching on the history of data science, I can’t help but mention that, for most of the most of the history of analytic techniques like machine learning, “Data Science” wasn’t even a term. Data science, and indeed even machine learning as the term is used now, didn’t come into the vernacular until 2013 or so. Before that, these types of analytic techniques were (somewhat derisively) referred to as “data mining,” to the extent they had a name at all.
Come to think of it, all sufficiently complex concepts are just extensions of simpler concepts. I guess my point here is that practical machine learning is just a normal field, no more or less difficult-to-grasp than anything else.
Two of the most important breakthroughs, as far as I can tell, were Convolutional and Recurrent Neural Networks, which provide the models with a way to take proximity into account, i.e. which pixels in an image, frames in a video, sounds in an audio recording, and/or words in a textual corpus, are near one another. Most machine learning techniques don’t care about proximity, but by using convolutions and recurrence, deep learning models systematically codify proximity, (surprisingly) enabling the models to process unstructured inputs.
By the way, railroad companies still exist. And they even use advanced physics sometimes, but only really indirectly, by, for example, relying on GPS which in turn relies on general relativity. But even in that case, executives of railroad companies don’t need to worry about the ins and outs of space-time curvature or whatever.
I hasten to add that I did not come up with that description, and I am not the “machine learning researcher” referred to in that post. I’m nowhere near smart enough to count as a “machine learning researcher” and nowhere cool enough to be quoted by Scott Alexander.
That’s not to say that I don’t think anybody’s job or field will change. I am genuinely nervous for anybody making creative products at scale, say, marketing copy writers or digital designers. If your job involves creating content which somebody directly pays you to make (as opposed to content paid for by advertising or fan subscriptions), I’m sorry to say the models may indeed be coming for you.
Yes, Search Engine Marketing, or SEM, is also an industry, but SEO is a much bigger annoyance, at least to me.
While it’s not technically “typing,” it may be doing something similar. Some models work by trying to predict the next character based on all previous characters, so each time ChatGPT pushes out a character, it really might be generating the following characters one-at-a-time, kind of like it’s typing.
And actually, if you look back at the about-in-titles question, it’s also not quite right. The second sentence says “In English the rules for capitalization in titles dictate that only the first word, proper nouns, and words that are normally capitalized (such as ‘I’ and ‘United’) should be capitalized.” I’m pretty sure this is wrong! These rules apply to normal sentences, not titles. It properly answers the actual “about” question, but the added color isn’t quite right, in a similar way to how the added color is wrong in the garden path sentence.
> It just correctly answers the question. No ads. No SEO. No nonsense. Just the answer.
It gave a simple, straightforward answer, but I'm not sure about the correctness. I did a search for this and found https://titlecaseconverter.com/blog/is-about-capitalized/ (this is the first link in response to the query «title case "about"», the double quotes are important) which says that the answer depends on which style guide you're following.